문제 상황
문제가 되는 쿼리는 다음과 같습니다.

참여한 모임을 조회할 때, 100만건 기준으로 데이터를 조회할 때 1.7초정도의 시간이 걸렸습니다. 가장 직관적이라고 생각해서 이런 구조로 쿼리를 날렸었는데, 생각보다 성능이 훨씬 좋지 않았습니다. 이유가 무엇일까요?
주최한 모임에 대해서는(group0_.host_id=?) 인덱스가 걸려있어서 빠르게 조회할 수 있지만, 참여한 모임을 조회하는 경우가 문제였습니다.
현재 참여한 모임을 조회하기 위해 서브쿼리로 participant 테이블에서 인원들을 가져와서, 그 인원들에 포함되어 있는지를 조회하는 방식이었습니다. 여기서 문제가 되는 점은 서브쿼리의 조건절에 외부 테이블 컬럼을 참조하는 부분이 문제였습니다.
- 외부 컬럼을 참조하는 내부 서브쿼리를 Correlated-subquery라고 하며, 외부에서 검색하는 행의 수만큼 서브쿼리가 실행됩니다. 따라서 서브쿼리가 너무 많이 날라가는 문제점이 발생했습니다.
- https://www.quora.com/How-do-correlated-subqueries-affect-performance
따라서, 쿼리를 두개로 나누는 것이 좋을 것 같습니다.
- 주최한 모임 조회
- 내가 참여한 모임 조회. 내가 참여한 모임을 조회하는 경우는, 먼저 participant 테이블에서 member_id로 group_id를 조회해온 다음, in절의 내부에 쿼리의 결괏값을 넣어주는 방식으로 작성하였습니다.
- Union을 사용하는 것이 가장 직관적이라고 생각했지만.. 아쉽게도 Union을 JPA에서는 지원하지 않았습니다.
어떻게 처리했을까?
빨간 네모 부분 in절 내부의 서브쿼리를 사전에 실행시켜서 결괏값을 미리 얻어온 다음 대입해주는 방식으로 로직을 교체해 보겠습니다. 현 시점에서 문제가 되는 코드는 다음과 같습니다.
@Query("SELECT g FROM Group g "
+ "WHERE g.participants.host = :member "
+ "OR ( :member IN (SELECT p.member.id FROM Participant p WHERE p.group = g) )")
List<Group> findParticipatedGroups(@Param("member") Member member);
위 로직을 다음과 같이 변경해서 테스트해 보겠습니다.
@Query("select distinct p.group.id from Participant p where p.member.id = :memberId")
List<Long> findGroupIdWhichParticipated(@Param("memberId") Long memberId);
@Query("SELECT g FROM Group g "
+ "WHERE g.participants.host = :member "
+ "OR g.id IN :participatedGroupIds")
List<Group> findParticipatedGroups(@Param("member") Member member,
@Param("participatedGroupIds") List<Long> participatedGroupIds);
단, 사용하는 서비스단에 추가 로직이 필요합니다.
public List<Group> findParticipatedGroups(Member member) {
List<Long> participatedGroupIds = groupSearchRepository.findGroupIdWhichParticipated(member.getId());
return groupSearchRepository.findParticipatedGroups(member, participatedGroupIds);
}
결과는 어떻게 되었을까요? 다음과 같이 두개의 쿼리가 따로따로 나가는 모습을 볼 수 있었습니다. 본인이 참여한 그룹들의 ID를 미리 구해두고, 이후 본인이 주최한 모임과 참여한 모임을 조회하는 모습을 볼 수 있었습니다.
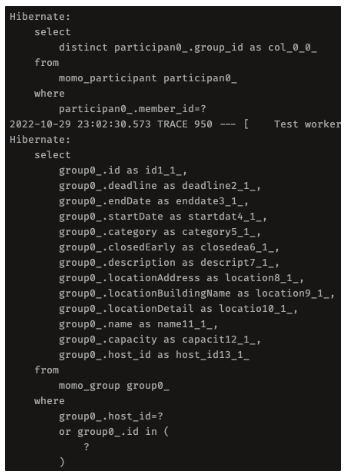
그렇다면.. 이제 대망의 성능 측정 시간입니다. 이렇게 조회를 하게 된다면 도합 0.03초정도의 조회 시간이 걸리는 것을 알 수 있습니다. 매번 불필요한 서브쿼리 조회가 날라가는걸 없애고 한번만 조회해서 다 가져온 다음에 in절로 묶어오니 훨씬 빠르게 개선되었다는 점을 알 수 있습니다.

'프레임워크 > Spring' 카테고리의 다른 글
| N+1 문제와 해결 방법 (0) | 2022.11.06 |
|---|---|
| 스프링 이벤트를 통한 양방향 의존성 풀기 (0) | 2022.11.04 |
| 더미데이터 생성기(Feat. BatchUpdate) (2) | 2022.10.29 |
| 이미지 파일 업로드 도입기 (0) | 2022.10.29 |
| 스프링의 생성자 주입 얕게 알아보기 (3) | 2022.10.25 |