내가 참여한 모임 조회. 내가 참여한 모임을 조회하는 경우는, 먼저 participant 테이블에서 member_id로 group_id를 조회해온 다음, in절의 내부에 쿼리의 결괏값을 넣어주는 방식으로 작성하였습니다.
Union을 사용하는 것이 가장 직관적이라고 생각했지만.. 아쉽게도 Union을 JPA에서는 지원하지 않았습니다.
어떻게 처리했을까?
빨간 네모 부분 in절 내부의 서브쿼리를 사전에 실행시켜서 결괏값을 미리 얻어온 다음 대입해주는 방식으로 로직을 교체해 보겠습니다. 현 시점에서 문제가 되는 코드는 다음과 같습니다.
@Query("SELECT g FROM Group g "
+ "WHERE g.participants.host = :member "
+ "OR ( :member IN (SELECT p.member.id FROM Participant p WHERE p.group = g) )")
List<Group> findParticipatedGroups(@Param("member") Member member);
위 로직을 다음과 같이 변경해서 테스트해 보겠습니다.
@Query("select distinct p.group.id from Participant p where p.member.id = :memberId")
List<Long> findGroupIdWhichParticipated(@Param("memberId") Long memberId);
@Query("SELECT g FROM Group g "
+ "WHERE g.participants.host = :member "
+ "OR g.id IN :participatedGroupIds")
List<Group> findParticipatedGroups(@Param("member") Member member,
@Param("participatedGroupIds") List<Long> participatedGroupIds);
결과는 어떻게 되었을까요? 다음과 같이 두개의 쿼리가 따로따로 나가는 모습을 볼 수 있었습니다. 본인이 참여한 그룹들의 ID를 미리 구해두고, 이후 본인이 주최한 모임과 참여한 모임을 조회하는 모습을 볼 수 있었습니다.
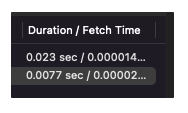
그렇다면.. 이제 대망의 성능 측정 시간입니다. 이렇게 조회를 하게 된다면 도합 0.03초정도의 조회 시간이 걸리는 것을 알 수 있습니다. 매번 불필요한 서브쿼리 조회가 날라가는걸 없애고 한번만 조회해서 다 가져온 다음에 in절로 묶어오니 훨씬 빠르게 개선되었다는 점을 알 수 있습니다.
본격적으로 성능 개선을 하기 위해 어느정도의 성능인지 테스트해야할 일이 생겼습니다. 테스트를 위해 더미데이터가 필요하였습니다. 대략 필요한 데이터의 수는 회원 100만건, 모임 100만건, 각 모임에 평균 5명의 참여자를 모이기 위해 참여 500만건 정도의 데이터가 필요하였습니다.
처음에는.. 데이터를 생성하려고 할 때 그냥 JPA를 이용하여 데이터를 저장하려고 하였습니다. 그냥저냥 무난할 줄 알았는데 100만건의 데이터를 넣기에는 너무나도 오랜 시간이 걸리더라구요. 끝이 보이지 않길래 이건 가망이 없다 싶어서 다른 방식을 찾아보다가, 코치와 크루에게 도움을 받아 JdbcTemplate의 BatchUpdate 방식을 사용하게 되었습니다.
BatchUpdate랑 일반 Update의 차이점
BatchUpdate를 사용하여 쿼리를 날려보니 생각보다 훨씬 훨씬 훨씬 더 더 더 많이 차이가 났습니다. 끝이 보이지 않는 100만건의 데이터 추가가 몇분안에 끝났습니다.
그렇다면 BatchUpdate는 어떻게 쿼리가 나가길래 빨리 끝나는 걸까요? 한번 직접 조회 로직을 비교해 보았습니다. 전체 테스트 코드는 다음과 같습니다.
@SpringBootTest
public class batchTest {
private static final String INSERT_SQL = "insert into momo_member(user_id, password, name, deleted) values (?, ?, ?, ?)";
@Autowired
JdbcTemplate jdbcTemplate;
@Autowired
EntityManager entityManager;
@Test
void batchUpdate() {
List<MemberDto> memberDtos = List.of(
new MemberDto("momo1", "momo1234", "momokingppp"),
new MemberDto("momo2", "momo1234", "momokingpppp")
);
System.out.println("데이터 출력 시작");
jdbcTemplate.batchUpdate(INSERT_SQL, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
MemberDto memberDto = memberDtos.get(i);
ps.setString(1, memberDto.userName);
ps.setString(2, memberDto.password);
ps.setString(3, memberDto.name);
ps.setBoolean(4, false);
}
@Override
public int getBatchSize() {
return memberDtos.size();
}
});
}
class MemberDto {
String userName;
String password;
String name;
public MemberDto(String userName, String password, String name) {
this.userName = userName;
this.password = password;
this.name = name;
}
}
}
로그가 잘 찍히는 것 같지 않아, MySQL WorkBench로 실제 데이터 추가 쿼리가 어떻게 추가되었나 살펴보겠습니다. 참고로, DB 로그를 테이블로 찍어보는 방법은 다음과 같습니다.
set global log_output = 'TABLE';
set global general_log = 'ON';
select * from mysql.general_log; // 로그 보기
truncate table mysql.general_log;
SET GLOBAL general_log = 'OFF'; // 이후 종료
여러개의 추가 쿼리가 하나의 insert문으로 묶여서 가는 모습을 볼 수 있습니다. 여러개의 insert문보다 하나의 insert문으로 여러개의 데이터를 묶어서 보내는 것이 더 속도가 빠를까요? 결론적으로는, 하나의 insert문이 훨씬 빠르다고 합니다. 하나의 insert문이 실행되기까지는 연결, 서버로 쿼리 전송, 구문 분석, 행 삽입, 인덱스 삽입, 연결 종료 등의 절차가 모두 포함되기 때문입니다.
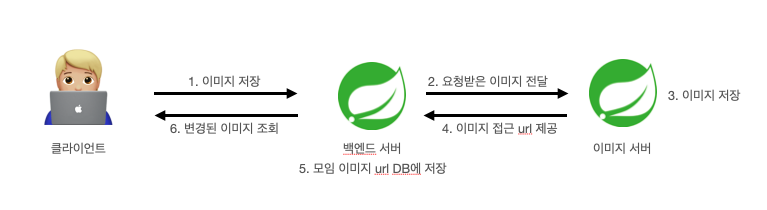
모두모여라 사이트에 보안상의 이유와 프로젝트 요구사항으로 인해 HTTPS를 적용하고자 하였습니다.
HTTP만을 사용하기에는 HTTP 메시지를 누구나 볼 수 있다는 문제점도 있고, 웹브라우저 자체에서 HTTP가 안전하지 않다고 표시되는 부분이 조금 신경쓰였습니다.
SpringBoot 설정 vs Nginx 설정 비교
HTTPS 적용에 앞서 HTTPS를 어떻게 적용해야 할 지 고민하였습니다. HTTPS 설정을 SpringBoot에서도 설정해 줄 수 있었고, Nginx에서도 설정할 수 있었습니다. SpringBoot에서 적용하나, Nginx에서 적용하나 간단하게 적용할 수 있었습니다. 둘 중 어느 방식을 사용해야 하는지 찾아보고 고민해 보았습니다.
먼저 SpringBoot에서의 설정입니다. yml 파일을 설정하는 방식으로 간단하게 적용 가능합니다.
Nginx와 SpringBoot 설정 자체는 둘 다 그렇게 복잡하지 않은 것 같습니다. 그렇다면 현재 프로젝트에 맞는 설정은 무엇인지 고민하고 적용해 보겠습니다.
모모 팀 프로젝트 아키텍처
현재 프로젝트에서는 Nginx를 각각 앞단에 두어 프론트와 백을 배포하고 있었습니다.
팀에서는 Nginx에 SSL을 적용하도록 결정하였습니다.
왜 Nginx에 SSL을 두었을까?
SpringBoot에 SSL을 두게 되면, Nginx를 없애야 합니다.
사용자는 Nginx에 접근하고 Nginx에서 서버로 접근하기 때문입니다.
처음엔 두 가지 방식 모두 적용 가능했습니다. 마음만 먹으면 Nginx를 제거할 수도 있는 등 Nginx를 자유롭게 사용할 수 있었기 때문입니다. 하지만 추후 저희 프로젝트에서는 Nginx를 사용하여 로드 밸런싱을 하였는데, 이 과정에서 다음 두 가지 이유로 인해 Nginx로 고정되게 되었습니다.
모든 서버에서 인증서와 비밀키를 가지고 있어야 할 필요가 있을까요?
클라이언트 ↔ Nginx, Nginx ↔ WAS 구조가 될 텐데, 스프링 부트에 SSL을 걸게 되면 클라이언트에서 Nginx로 접근하려고 할 때는 HTTP 요청이지 않을지.. 오히려 클라이언트에서 NginX로 전달하는 HTTP 메시지를 암호화하는 것이 의미가 있는 것이 아닐까요?
HTTPS의 문제점??
그렇다면 HTTPS를 도입하기 전에.. HTTPS를 도입했을 때의 문제점은 없나 찾아 보았습니다.
성능 상의 문제, HTTPS는 HTTP 대비 느리다는 말이 있었습니다.
SSL 핸드셰이크, 전송 전후로 암복호화가 일어난다면 속도 차이가 있을 것 같았습니다.
실제로 어느정도의 속도 차이가 있을지 테스트를 진행해 보겠습니다. 이 때 접근 대상은 API 문서에 대한 접근 테스트입니다.
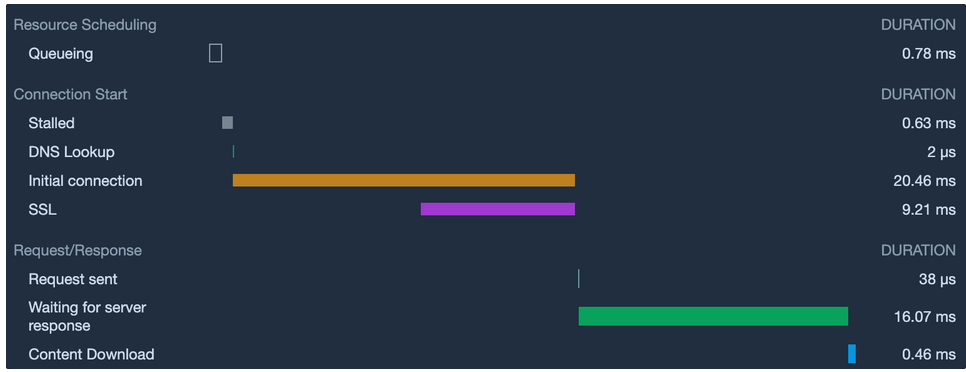
먼저, HTTPS를 사용했을 경우의 응답 시간입니다.
HTTPS의 응답 시간
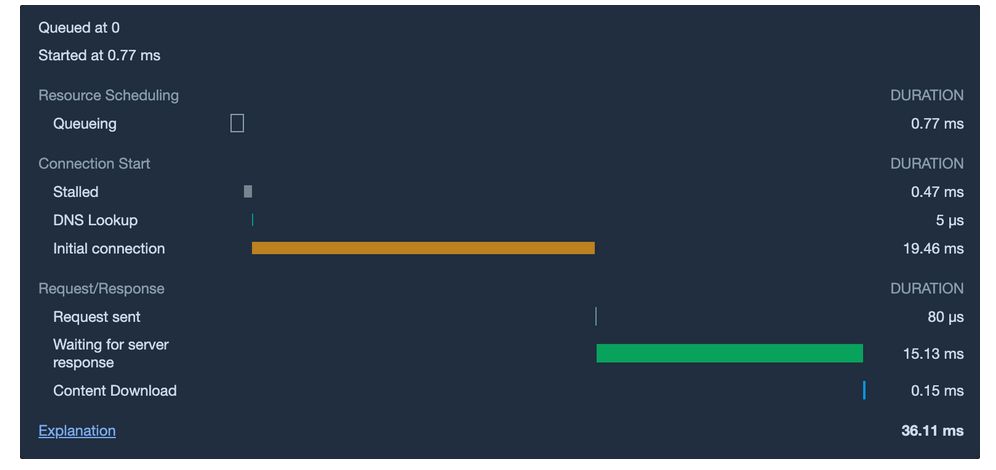
다음으로, HTTP를 사용했을 경우의 응답 시간입니다.
결론
예상한 대로 HTTPS가 대략 1ms정도 느린 결과가 도출되었습니다.
목표로 하는 동시 접속 인원수가 적어 1ms정도의 시간은 개인적으로 고려해야 할 정도는 아니라고 판단되었습니다. 이 부분은 팀적으로도 동의되어 HTTPS를 적용하는 쪽으로 결정하였습니다.
IoC란, 메소드나 객체의 호출 작업을 개발자가 하는것이 아닌 외부에서 처리하는 것을 말합니다. 즉, IoC 컨테이너에서 DI를 하게 됩니다.
스프링의 IoC 컨테이너로는 ApplicationContext를 사용합니다.
ApplicationContext
애플리케이션에서 IoC를 적용해서 관리할 모든 오브젝트에 대한 생성과 관계설정을 담당합니다.
… 어떻게?
빈을 생성해서 관리하는것 까진 알겠는데 빈에 달려있는 의존성은 어떻게 주입하는 건지 문득 궁금해졌습니다. A → B로 의존되어 있다면 빈 생성이 어떻게 이루어질까요? 다음과 같은 테스트 코드를 작성해 보겠습니다.
@Controller
public class UserController {
private final UserService userService;
public UserController(UserService userService) {
this.userService = userService;
}
}
@Service
@RequiredArgsConstructor
public class UserService {
private final UserDao userDao;
@PostConstruct
public void construct() {
System.out.println("UserService 생성 완료");
}
}
아주 간단한 주입받는 테스트 코드입니다. 객체가 생성된 직후의 상황을 테스트하기 위해 @PostConstruct 어노테이션을 사용하였습니다.
저는 DI를 미션을 통해 리플렉션을 사용하여 직접 구현해 보았는데도 불구하고 아직도 어떻게 DI가 일어나는지 와닿지 않았습니다. 그렇다면 실제 주입 과정이 어떻게 일어나는지 디버그를 찍어보며 확인해 보았습니다. 참고로 생성자 주입의 경우입니다.
AbstractBeanFactory의 getBean()을 통해 빈을 생성하려고 합니다. 이 때, 주입을 처리해야 하므로 다음 단계로 이동합니다.
싱글톤 빈이므로 싱글톤 빈 관련 로직이 수행되며 ConstructorResolver.autowireConstructor() 메서드를 사용하여 주입을 위해 사용할 생성자를 가져옵니다.
DefaultListableBeanFactory.doResolveDependency() 메서드에서 descriptor을 통해 빈 이름을 가져오고, 가져온 빈 이름으로 빈 객체를 조회합니다.
descriptor : 주입되어야 하는 의존성에 대한 명세
descriptor.resolveCandidate() 메서드를 사용하여 주입받아야 하는 빈 이름을 넣어 다시한번 getBean() 메서드를 호출합니다. 빈이 만들어지지 않았다면 위의 내용이 반복됩니다.
생략된 내용이 많긴 하지만.. 디버깅을 찍어보면서 알게 된 내용은 여기까지입니다. 결론적으로 A → B → C 순으로 의존하고 있다면, 빈 C부터 만들어지고 마지막으로 빈 A가 만들어지는 것을 알 수 있었습니다.
한가로운 어느 일요일, 저는 평소와 같이 열심히 테스트 코드를 작성하고 있었습니다. 테스트 코드를 작성하던 중, 언젠가 테스트 코드에서는 의존성 주입이 안된다는 사실을 알고 있냐는 크루의 물음이 떠올랐습니다. 그동안 편의를 위해 Autowired를 마구 쓰던 저는 이번 기회에 한번 테스트해보자는 마인드로 생성자 주입을 하도록 코드를 변경해 보았습니다.
그 결과…
@SpringBootTest
public class ProductServiceTest {
private final ProductService productService;
public ProductServiceTest(ProductService productService) {
this.productService = productService;
}
...
으악
역시 안되는군요.. 크루는 거짓말을 하지 않았습니다. 그렇다면 왜 되지 않는 걸까요? @SpringBootTest를 써 주었으니 문제가 없는게 아닐까요? 대충 에러 메세지를 보아 하니.. ProductService라는 파라메터에 대한 ParameterResolver가 등록되지 않았다고 뜨는군요. 이 부분을 한번 구글의 힘을 빌려 찾아 보겠습니다.
해결법 자체는 생성자에 있는 파라메터를 제거하고 @BeforeEach에서 초기화를 해주거나 @Autowired로 필드를 초기화한다고 나오는 거 같습니다. 해결법은 알겠고.. 원인은 무엇일까요?
무엇이 문제였을까?
@SpringBootTest를 붙이게 되면 Junit Jupiter에 SpringExtension이 자동으로 등록되어 사용됩니다. 조금 소스를 까보면서 해결책이 있을지 찾아보겠습니다.
* <p><strong>WARNING</strong>: If a test class {@code Constructor} is annotated
* with {@code @Autowired} or automatically autowirable (see {@link TestConstructor}),
* Spring will assume the responsibility for resolving all parameters in the
* constructor. Consequently, no other registered {@link ParameterResolver}
* will be able to resolve parameters.
읽어보니 @Autowired가 달린 Constructor나 TestConstruct 어노테이션을 사용한 경우에 대해서만 생성자 내의 모든 파라메터를 처리한다고 하네요. 추측하건데 프로덕션 코드에서는 Autowired 어노테이션을 생략 가능하지만, SpringExtension에서는 Autowired 어노테이션이 생략 불가능해서 위와 같은 에러가 떴던 거 같습니다.
제 생각으로는 아마, 테스트 클래스를 관리하는 주체가 Spring이 아닌 Junit5이기 때문에 Junit의 방식을 따라야 하는데, Junit에서는 빈을 주입하기 위해서는 Junit에서 제공하는 ParameterResolver를 통해 주입해야 하기 때문인 것 같습니다. Junit의 파라메터 중 어떤 파라메터를 스프링의 ApplicationContext에서 주입받아야 하는지 구분하기 위해 Autowired 어노테이션에 의존하게 된 것 같습니다.
결론적으로, Autowired는 필수적으로 써주어야 합니다. 주석 내에 @TestConstruct라는 어노테이션이 있어 이를 사용해 보겠습니다. @TestConstruct는 생성자 주입을 어떻게 처리할 지 결정한다고 보는게 가장 좋을 것 같습니다. ALL 옵션인 경우, 모든 생성자에 Autowired가 달려있는 것으로 간주하며 생성자 주입을 시켜 줍니다. ANNOTATED 옵션인 경우 관련 어노테이션(@Autowired, @Value, …)이 붙어있는 경우에만 생성자 주입이 동작합니다.
@SpringBootTest
@TestConstructor(autowireMode = AutowireMode.ALL)
public class ProductServiceTest {
private final ProductService productService;
public ProductServiceTest(ProductService productService) {
this.productService = productService;
}
JVM이란 Java 응용 프로그램을 실행하는 런타임 엔진 역할을 합니다. JVM에서 실제로 자바 코드상에 존재하는 main() 메서드를 호출하며, JRE(Java Runtime Environment)의 일부입니다.
Java 어플리케이션은 한 시스템에서 Java 코드를 작성하더라도 변경 없이 다른 Java를 지원하는 시스템에서 실행할 수 있는 성질이 있는데, JVM을 사용하기 때문입니다.
JVM의 동작 과정
Java 파일을 컴파일할 때, .java 파일에 있는 동일한 클래스 이름을 가진 클래스 파일이 컴파일러에 의해 생성됩니다. class 파일은 실행할 때 다양한 단계를 거치는데, 이 단계들이 바로 전체 JVM의 동작 과정입니다.
전체 JVM 구조
Class Loader
주로 세가지 역할을 담당합니다.
Loading
Linking
Initialization
Loading
ClassLoader가 필요한 클래스들을 불러와서 적재시키는 과정입니다.
Initialization
초기화 단계에서 모든 정적 변수는 코드 및 정적 블록(있는 경우)에 정의된 값으로 할당됩니다. 클래스 내부에서 위에서 아래로, 클래스 계층에서 부모에서 자식으로 실행됩니다. 일반적으로 세개의 클래스 로더가 존재합니다.
클래스 불러오는 과정
클래스를 불러올 때, Bootstrap Class Loader에서 찾을 수 없다면 Extension ClassLoader, Extension ClassLoader에서 찾을수 없으면 Application ClassLoader을 찾아 보고, 최종적으로 없다면 ClassNotFoundException이 발생합니다.
Class Loader의 종류
Bootstrap Class loader
JAVA_HOME/jre/lib 디렉토리에 존재하는 핵심 자바 API 클래스를 로드합니다.
Extension Class loader
확장 디렉토리(JAVA_HOME/jre/lib/ext) 또는 기타 디렉토리(java.ext.dirs 시스템 속성에 의해 지정)에 있는 클래스들을 로드합니다.
ExtClassLoader 클래스에 의해 구현됩니다.
System/Application class loader
Extension Class loader의 자식입니다.
애플리케이션 클래스 경로에서 클래스를 불러오는 역할을 합니다. 즉, 개발자들이 작성한 클래스 파일이 불러와 집니다.
내부적으로 java.class.path에 매핑된 환경 변수를 사용하며, AppClassLoader 클래스에 의해 구현됩니다.
5. 이후 다시 OAuth & Permissions로 가면 봇의 OAuth Token이 발급됩니다.
슬랙 메세지 전송
슬랙 봇도 만들고 OAuth Token도 발급받았으니 본격적으로 슬랙 메세지를 전송해 봅시다.
슬랙 메세지 전송 API는 다음과 같습니다.
채널 ID는 채널 정보의 하단에 존재한다.
언뜻 살펴보기에.. Authorization 헤더에 위에서 받아온 토큰을 입력해 주고, channel에 채널ID 라는걸 넣어주면 잘 동작할 것 같습니다. 그렇다면 ChannelID는 뭘까요? 맨 아래에 채널 ID라는게 따로 존재하는 모습을 볼 수 있습니다. 이제 전달해주기 위한 모든 데이터들을 다 얻었으니 본격적으로 슬랙에 메시지를 던져보기 위한 코드를 작성해 보겠습니다. 외부 API를 호출하므로 RestTemplate를 통해 Api를 사용하겠습니다.
public void index() throws JsonProcessingException {
final var token = "슬랙봇_토큰";
final var url = "https://slack.com/api/chat.postMessage";
final var channelID = "채널아이디";
HttpHeaders httpHeaders = new HttpHeaders();
httpHeaders.add(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE);
httpHeaders.add(HttpHeaders.AUTHORIZATION, "Bearer " + token);
SlackMessage slackMessage = new SlackMessage(channelID, "hello world!");
ObjectMapper objectMapper = new ObjectMapper();
String jsonData = objectMapper.writeValueAsString(slackMessage);
HttpEntity<String> request = new HttpEntity<>(jsonData, httpHeaders);
String response = restTemplate.postForObject(url, request, String.class);
System.out.println(response);
}
사실 위 방식을 그대로 잘 따라했다면 에러가 뜹니다..ㅎ 코드를 짜고 요청을 계속해서 날려보아도 봇이 채널에 존재하지 않는다는 에러가 발생하였습니다. 구글링 결과 봇 권한을 더 주어야 한다고 슬랙 봇 권한을 보니 채널에 참여하는것도 권한을 줘야 한다고 합니다. 따로 권한을 부여하여 주고 채널을 새롭게 파서 채널에 봇을 입장시켜 줍시다~
Java의 log4j의 후속버전입니다. log4j의 아키텍처 기반으로 재작성 되었으며, slf4j을 지원하기 때문에 다른 logger로 얼마든지 바꿀수 있게 구현되어 있습니다.
로그 레벨
사전 지식으로 로그 레벨에 대해서 알아야 합니다.
ERROR : 요청을 처리하는 중 오류가 발생한 경우 표시하는 로그입니다.
WARN : 처리 가능한 문제, 향후 시스템 에러의 원인이 될 수 있는 경고성 메시지를 나타냅니다.
INFO : 상태변경과 같은 정보성 로그를 나타냅니다.
DEBUG : 프로그램을 디버깅하기 위한 정보를 표시합니다.
TRACE : 추적 레벨을 Debug보다 훨씬 상세한 정보를 나타냅니다.
로그 레벨의 경우는 역순으로, ERROR이 가장 높고, TRACE가 가장 낮은 레벨입니다.
Logging With Springboot
spring-boot-starter-web 의존성 추가
application.yml 또는 logback-spring.xml에서 설정하는것이 포인트입니다.
설정할 부분은 대략 다음과 같습니다.
콘솔, 파일, DB 등 로그를 출력하는 방법을 지정하는 Appender
출력할 곳을 정하는 logger
logback 설정 파일 경로는 /resources/logback-spring.xml입니다.
Configuration
Appender에서 콘솔에 출력되는 형식을 지정합니다.
Pattern에서 지정한 방식대로 시간/레벨 등이 설정된 후 콘솔에 메시지를 저장합니다.
filter, encoder, policy 등을 지정할 수 있습니다.프로젝트에서는 로그가 특정 크기(10MB)가 되면, 새로운 로그를 저장하도록 구현할 계획이므로 RollingFileAppender을 사용합니다.
RollingFileAppender엔 등록되어 있는 몇가지 정책(RollingPolicy)들이 있습니다. 이 중 파일 크기 기반으로 정책을 설정할 계획이므로 SizeBasedTriggeringPolicy를 사용하였습니다. 또한, 저장되는 로그 파일을 10개씩 관리하기 위해 FixedWindowRollingPolicy를 같이 사용하였습니다.
레벨에 따라서 적용되는 필터입니다. 이번 예시에서는 ERROR 레벨에서만 로그를 찍도록 하기 위해 ERROR 단계에서의 onMatch 속성을 ACCEPT로 설정하고, ERROR 레벨이 아니라면 로그를 찍지 않도록 하기 위해 ERROR 레벨이 아니라면 무시하도록 DENY를 걸어주었습니다. 참고로 값들에 대한 설명은 다음과 같습니다.
이번 예제에서는 rollingPolicy와 triggeringPolicy를 사용하였습니다. triggeringPolicy는 rollover가 발생하는 시점이며, rollingPolicy는 rollover 발생 시 처리 방식에 대해 명시하였습니다. TriggeringPolicy인 SizeBasedTriggeringPolicy로 인해10MB의 파일 크기가 넘어간다면 FixedWindowRollingPolicy가 발생하여 <file>에 적힌 파일명에 숫자를 붙여서 다른 파일로 보관하며, 10개의 파일을 보관합니다.
테스트
적용을 다 했으면, 이제 직접 테스트해 봅시다. 예외를 터트리면 ERROR 단계일거 같으니, 한번 아무렇게나 예외를 터트려 봅시다.
public Group findGroup(Long id) {
throw new IllegalArgumentException("hello world!");
//return groupSearchRepository.findById(id)
// .orElseThrow(() -> new GroupException(NOT_EXIST));
}
실행했는데 로그 파일은 생성되지만, 슬프게도 아무 로그도 찍히지 않는 문제가 발생했습니다. 문제가 무엇일까요? 답은 예외를 터트린다고 하더라도 로그 레벨이 ERROR이 아니라는 점입니다.
즉, 예외를 처리하는 ControllerAdvice에서 Logger.error 메서드를 호출하여서 명시적으로 ERROR 로그 레벨의 로그를 출력해 주면 됩니다. 이때 Exception 객체를 넘겨주면, StackTrace도 함께 출력됩니다.
테스트 해보다가 참고로 알게된 점은.. 서비스 테스트에서 예외를 터트리더라도 Advice로는 가지 않는 문제가 있었습니다. ControllerAdvice는 컨트롤러 단에서 터지는 예외에 대해서만 처리를 하기 때문에 서비스 테스트에서 백날 예외를 터트려 봐야 Advice로 들어가지 않는다고 하더라구요.. 이거때문에 삽질을 좀 오랜시간 했습니다..ㅠ
서비스를 Transaction 서비스, 비즈니스 서비스로 나눈다고 하면 이 중 Transaction 서비스를 부가기능이라고 생각하면 됩니다.
우리가 원한건 비즈니스 서비스고, 부가적인 처리가 필요하다는 관점
주로 인프라 관련 처리들이 부가기능
스프링은 어드바이스를 인터셉터로 모델링하고 조인 포인트 주변에 인터셉터 체인 유지
포인트 컷(Pointcut)
어드바이스를 적용할 조인 포인트를 선별하는 모듈
타겟(Target)
부가기능(Advice)을 적용할 대상
프록시(Proxy)
클라이언트와 타겟 사이에서 부가기능을 제공하는 객체
스프링에서 프록시는 JDK 동적 프록시 또는 CGLIB 프록시로 구현
스프링에서의 프록시를 제공하는 두가지 방법 : 리플렉션(JDK), CGLIB 라이브러리 사용
스프링은 JDK가 기본, 스프링 부트에서 CGLIB 라이브러리 사용
JDK 프록시 → 메서드 단위, 인터페이스여야만 사용 가능
동적 프록시(Dynamic Proxy)
공식 문서의 설명을 따다 가져오면 다음과 같습니다.
동적 프록시 클래스 는 클래스 인스턴스 의 인터페이스 중 하나를 통한 메서드 호출이 균일한 인터페이스를 통해 인코딩되고 다른 객체에 전달되도록 런타임에 지정된 인터페이스 목록을 구현하는 클래스입니다.
말이 너무 어렵습니다.. 구현된 코드를 보면서 하나씩 알아보면 좋을 것 같습니다ㅎㅎ 구현된 코드의 요구사항은 다음과 같습니다.
Transactional 어노테이션이 붙어있는 메서드가 호출된다면, 해당 메서드가 온전히 실행되면 commit, 예외가 발생하면 rollback 한다.
public class TransactionHandler implements InvocationHandler {
private final PlatformTransactionManager transactionManager;
private final AppUserService appUserService;
public TransactionHandler(PlatformTransactionManager transactionManager, AppUserService appUserService) {
this.transactionManager = transactionManager;
this.appUserService = appUserService;
}
@Override
public Object invoke(final Object proxy, final Method method, final Object[] args) throws Throwable {
Method realMethod = Arrays.stream(appUserService.getClass().getDeclaredMethods())
.filter(m -> compareTwoMethodSame(m, method))
.findAny()
.orElseThrow();
if (realMethod.isAnnotationPresent(Transactional.class)) {
final var transactionStatus = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
Object methodReturnValue = method.invoke(appUserService, args);
transactionManager.commit(transactionStatus);
return methodReturnValue;
} catch (Exception e1) {
transactionManager.rollback(transactionStatus);
throw new DataAccessException();
}
} else {
try {
return method.invoke(appUserService, args);
} catch (Exception e1) {
throw new DataAccessException();
}
}
}
private boolean compareTwoMethodSame(Method a, Method b) {
if (!a.getName().equals(b.getName())) {
return false;
}
Class<?>[] aParams = a.getParameterTypes();
Class<?>[] bParams = b.getParameterTypes();
if (aParams.length != bParams.length) {
return false;
}
for (int i = 0; i < aParams.length; i++) {
if (!aParams[i].getTypeName().equals(bParams[i].getTypeName())){
return false;
}
}
return true;
}
}
위 코드에서 중점이 되는 부분은 invoke 메서드입니다. 메소드가 호출되면, invoke()가 호출되며 전달받은 Method 객체를 사용하여 메서드를 호출하기 전, 후로 실행 로직을 처리할 수 있습니다. 실제 메소드가 호출되는 부분문 method.invoke() 입니다.
그렇다면 사용 측면에선 어떻게 사용하면 될까요? java.lang.reflect.Proxy 클래스의 newProxyInstance 메소드를 사용하여 프록시 객체를 만들어 줄 수 있습니다.
final var appUserService = new AppUserService(userDao, userHistoryDao);
final InvocationHandler invocationHandler = new TransactionHandler(platformTransactionManager, appUserService);
final UserService userService = (UserService) Proxy.newProxyInstance(
UserService.class.getClassLoader(),
new Class[]{UserService.class},
invocationHandler
);
주의할 점은, UserService는 인터페이스 타입입니다. Proxy의 newProxyInstance 메서드의 두번째 인자로 반드시 인터페이스 타입을 명시해 주어야 합니다. 자세한 사용 설명은 다음 사이트를 참고하시면 좋을 것 같습니다.
스프링의 빈을 기반으로 AOP 프록시를 만들어 주는 객체입니다. 3개의 역할이 필요합니다.
Advice
부가기능을 담고 있는 클래스입니다.
Pointcut
Advice가 적용될 조인 포인트를 선별합니다.
조인 포인트는 Advice가 적용 될 위치라고 생각하시면 됩니다.
Advisor
Pointcut과 Advice를 가지고 있는 객체입니다.
AOP의 Aspect와 같습니다.
Advice
public class TransactionAdvice implements MethodInterceptor {
private final PlatformTransactionManager transactionManager;
public TransactionAdvice(PlatformTransactionManager transactionManager) {
this.transactionManager = transactionManager;
}
@Override
public Object invoke(final MethodInvocation invocation) throws Throwable {
TransactionStatus transaction = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
Object methodReturnValue = invocation.proceed();
transactionManager.commit(transaction);
return methodReturnValue;
} catch (Exception e) {
transactionManager.rollback(transaction);
throw new DataAccessException();
}
}
}
Pointcut
public class TransactionPointcut extends StaticMethodMatcherPointcut {
@Override
public boolean matches(final Method method, final Class<?> targetClass) {
return method.isAnnotationPresent(Transactional.class);
}
}
Advisor
public class TransactionAdvisor implements PointcutAdvisor {
private final TransactionAdvice advice;
private final TransactionPointcut pointcut;
public TransactionAdvisor(TransactionAdvice advice, TransactionPointcut pointcut) {
this.pointcut = pointcut;
this.advice = advice;
}
@Override
public Pointcut getPointcut() {
return pointcut;
}
@Override
public Advice getAdvice() {
return advice;
}
@Override
public boolean isPerInstance() {
return true;
}
}
각각에 맞추어서 구현이 완료되었다면, 이제 ProxyBeanFactory 객체를 생성하여 설정해 주고 인스턴스를 생성하면 됩니다.
우선 프록시를 적용할 인스턴스와 Advisor을 미리 만들어 둡니다.
ProxyBeanFactory에 인스턴스와 Advisor을 넣어주고, getObject() 메서드로 프록시 객체를 얻어올 수 있습니다.
final ProxyFactoryBean proxyFactoryBean = new ProxyFactoryBean();
final UserService temporaryUserService = new UserService(userDao, userHistoryDao);
TransactionAdvice advice = new TransactionAdvice(platformTransactionManager);
final TransactionAdvisor advisor = new TransactionAdvisor(
advice,
new TransactionPointcut()
);
proxyFactoryBean.setTarget(temporaryUserService);
proxyFactoryBean.addAdvisor(advisor);
final UserService userService = (UserService) proxyFactoryBean.getObject();
DefaultAdvisorAutoProxyCreator
위 코드를 보면, 프록시 객체를 만들기 위해 많은 노력이 드는 것을 볼 수 있습니다. ProxyBeanFactory도 생성해야 하고.. Advice도 매번 만들어주어야 하고.. 인스턴스도 만들어주어야 하고..
이러한 부분들을 DefaultAdvisorAutoProxyCreator을 빈 등록만 해두면 쉽게 사용할 수 있습니다.
@Configuration
public class AopConfig {
@Bean
public TransactionAdvice transactionAdvice(PlatformTransactionManager platformTransactionManager) {
return new TransactionAdvice(platformTransactionManager);
}
@Bean
public TransactionPointcut transactionPointcut() {
return new TransactionPointcut();
}
@Bean
public TransactionAdvisor transactionAdvisor(TransactionAdvice advice, TransactionPointcut pointcut) {
return new TransactionAdvisor(advice, pointcut);
}
@Bean
public DefaultAdvisorAutoProxyCreator defaultAdvisorAutoProxyCreator() {
return new DefaultAdvisorAutoProxyCreator();
}
}
사실 이 부분은 이해가 잘 되지 않았습니다. 위의 ProxyFactoryBean은 명시적으로 프록시 객체를 만들어 주었거든요. 이 부분에서는 프록시 빈을 만드는 느낌은 아니었습니다.
이 부분은 찾아보니 빈 후처리기에서 동작하며 Advisors를 기반으로 AOP 프록시 객체를 만들어 준다고 합니다. 자세한 내용은 다음과 같습니다.